در این مقاله به تشریح انواع مدل های معادله ساختاری و کاربرد آنها می پردازیم.
1- مدل های با معرف های چندگانه و علل چندگانه
معرف های چندگانه و علل چندگانه نوع خاصی از مدل های معادله ساختاری را معرفی می کند و به طور مخفف با
MIMIC (Multiple Indicator and Multiple Causes)
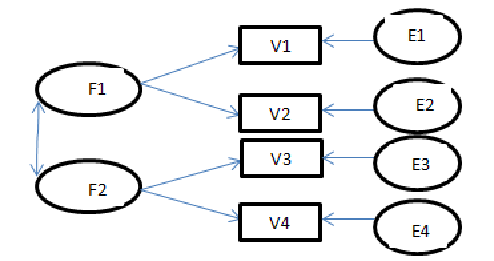
نشان داده می شود. مدل های MIMIC شامل کاربرد متغیرهای پنهانی است که بوسیله متغیرهای مشاهده شده پیش بینی می شوند. این موضوع را با مثالی از یورسکوگ و سوربوم (1996) بیان می کنیم که در آن یک متغیر پنهان (مشارکت اجتماعی) بوسیله رفتن به کلیسا، عضویت های گروهی و دیدار دوستان تعریف شده است. همچنین این متغیر بوسیله متغیرهای مشاهده شده درآمد، اشتغال و تحصیلات پیش بینی می شود.
متغیر پنهان مشارکت اجتماعی با پیکان هایی به سه معرف متصل شده است که هرکدام دارای مقداری خطای اندازه گیری هستند. همچنین سه پیکان از متغیرهای مشاده شده به سمت متغیر مشارکت اجتماعی نشانه رفته است. این متغیرهای مشاهده شده با یکدیگر همبستگی دارند. پس از بررسی معناداری متغیرها در صورت لزوم متغیرهای غیرضروری از مدل حذف می شوند.
2- مدل های گروه های چندگانه
تحلیل مدل های گروه های چندگانه با بررسی مدل های اندازه گیری و یکسانی اندازه گیری بین گروه ها آغاز می شود . چنین تحلیلی قبل از بررسی فرضیه های وجود تفاوت معنادار در ضرایب ساختاری بین گروه ها ضروری است. کاربرد این مدل شامل آزمون تفاوت بین برآورد پارامترها برای گروه های چندگانه می باشد.
به عنوان نمونه می توانیم به مثال ارائه شده توسط آربوکل و تکه (1999) اشاره کنیم. در این تحقیق تفاوت های ارزیابی از جذابیت و ارزیابی از توان آکادمیک بین دو گروه دختران و پسران مورد بررسی قرار گرفته است.
3- مدل های چند سطحی
مدل های چندسطحی در مدل سازی معادله ساختاری به علت ماهیت سلسله مراتبی داده ها در یک طرح تحقیقی آشیانه ای به این نام خوانده می شوند. به عنوان مثال پیشرفت تحصیلی یک دانشجو در کلاس ها پایه ریزی شده است، بنابراین دانشجویان در کلاس ها آشیان شده، معلمان درمدارس آشیان شده هستند و مدارس در مناطق آشیان شده اند. طرح پژوهشی آشیانه ای با یک طرح پژوهشی متقاطع متفاوت است.
علاقه ما در این نوع از طرح ها، با ملاحظه ماهیت خوشه ای شده داده ها، به اثرات در سطوح متفاوت است. EQS دارای سه روش اجرای مدل چند سطحی بر اساس یک متغیر خوشه ای است که عبارتند از :
- الف) حداکثر درستنمایی با استفاده از الگوریتم انتظار/ ماکزیمم کردن.
- ب) برآورد موتن مبتنی بر حداکثر درستنمایی
- ج) مدل خطی سلسله مراتبی.
روش چندسطحی ML با استفاده از برآورد حداکثر درستنمایی، الگوریتم EM را در دو گام به منظور برآورد پارامترها و خطاهای معیار به کار می برد. الگوریتم اول گام انتظار است(E) که در آن ماتریس های کواریانس درون و بین سطحی با استفاده از تکرار برآورد می شوند. گام دوم به حداکثر رسانی (ماکزیمم سازی) است که در آن اگر معیار همگرایی برقرار باشد، برآوردهای حداکثر درستنمایی و خطاهای معیار تولید می شوند.
تحلیل چندسطحی با ML تنها برای مدل های دوسطحی طراحی شده است. تفسیر مدل های چندسطحی که بیشتر از دو سطح آشیان شده دارند مشکل است. اما با این حال مدل های خطی سلسله مراتبی در رگرسیون با سه سطح از متغیر مشاهده شده تحلیل شده اند.
مدل های خطی سلسله مراتبی در EQS برای تحلیل تا 5 سطح با استفاده از متغیرهای پنهان طراحی شده اند. در مدل های خطی سلسله مراتبی ابتدا معادله سطح اول معادله سطح اول برای هر خوشه اجرا شده و پارامترهای برآورد شده ذخیره می شوند و سپس برای استفاده در معادله سطح دو مورد استفاده قرار می گیرند. بنابراین معادله سطح دوم داده های خود و همچنین پارامترهای برآورد شده از سطح اول را مورد استفاده قرار می دهد.
مدل چند سطحی خطی سلسله مراتبی در EQS مشابه برنامه های چند سطحی حداکثر درستنمایی و برآورد موتن بر مبنای حداکثر درستنمایی است به جز اینکه مجموعه دومی از داده ها نیز در آن تعریف می شوند.
4- مدل های ترکیبی
مدل های ترکیبی در مدل سازی معادلات ساختاری شامل تحلیل متغیرهای مشاهده شده ای است که از دو نوع مقوله ای و پیوسته هستند. EQS امکانی را فراهم می آورد که دو نوع متغیرهای مقوله ای و پیوسته در مدل حضور داشته باشند.
5- مدل میانگین های ساختمند
کاربرد مهم دیگر مدل سازی معادله ساختاری، آزمون تفاوت میانگین های گروهی برای متغیرهای مشاهده شده یا پنهان است. این کاربرد در واقع حالت توسعه یافته تحلیل پایه رویکرد واریانس است جایی که تفاوت میانگین ها برای متغیرهای مشاهده شده آزمون می شوند. آزمون تفاوت میانگین ها بین متغیرهای مشاهده شده در مدل سازی معادله ساختاری مشابه با تحلیل واریانس و کواریانس است.
در مورد آزمون مربوط به متغیرهای پنهان به عنوان مثال آزمون تفاوت میانگین متغیر پنهان توان شفاهی بین پسران دانشگاهی و غیر دانشگاهی در پایه های پنجم و هفتم را می توان در نظر گرفت. در این مثال نمرات افراد در خواندن و نوشتن، متغیر پنهان را در پایه های پنجم و هفتم می سازد.
6- مدل های چند خصیصه ای-چند روشی
این مدل ها با هدف نشان دادن خصایص چندگانه ارزیابی شده به وسیله سنجه های چندگانه مورد استفاده قرار می گیرند. به عنوان مثال می توان از پیشرفت و انگیزه دانش آموزان (خصیصه ها) نام برد که به وسیله نمره دهی معلمان و نمره دهی خود دانش آموزان (روش ها) ارزشیابی شده اند. این مدل ها اطلاعاتی را برای تعیین اعتبار سازه تدارک می بینند.
ماتریس چندخصیصه ای-چند روشی ضرایب اعتبار همگرا، ضرایب اعتبار ممیز و ضرایب قابلیت اعتماد را در طول قطر منعکس می کند. ضرایب قابلیت اعتماد نشان دهنده سازگاری درونی نمرات بر روی ابزار است و بنابراین باید حدودا بین 0.85 تا 0.95 یا بالاتر قرار گیرد. ضرایب اعتبار ممیز، همبستگی های بین سنجه های خصایص مختلف (سازه ها) با استفاده از روش یکسان (ابزار) است و بنابراین انتظار می رود بسیار پایین تر از ضرایب اعتبار همگرا و یا ضرایب قابلیت اعتماد ابزار باشد.
7- مدل یگانگی همبسته
این مدل ها توسط مارش و گریسون (1995) و وتکه (1996) به عنوان جایگزینی برای مدل های سنتی چندخصیصه ای-چند روشی طرح شده اند. در مدل های یگانگی همبسته هر متغیر به عنوان یک عامل خصیصه و یک جمله خطا، اثر پذیرفته و عامل های روشی نیز وجود ندارند. اثرات روش به وسیله جملات خطای همبسته هر متغیر به حساب می آیند.جملات خطای همبسته تنها بین متغیرهای سنجش شده به وسیله روش مشابه وجود دارند.
انواع متفاوتی از مدل های یگانگی همبسته می توانند تحلیل شوند. به عنوان مثال می توان به از یک عامل عام با یگانگی همبسته، دو عامل همبسته با یگانگی غیرهمبسته و دو عامل غیرهمبسته با یگانگی همبسته نام برد. مارش و گریسون نشان می دهند که وجود کاهش معنادار در برازش بین یک مدل با خصایص همبسته اما جملات غیر همبسته و یک مدل با خصایص همبسته همراه با جملات خطای همبسته، نشانه وجود اثرات روشی است.
8- مدل های عاملی مرتبه دوم
این مدل ها هنگامی طرح می شوند که مدل های مرتبه اول به وسیله ساختار عاملی مرتبه بالاتر تبیین شوند. به عنوان مثال براساس داده های هولتزینگر و اسواینفورد نه متغیر روانشناختی، تعریف کننده سه عامل مشترک (بصری، شفاهی و سرعت) هستند. این سه عامل به نوبه خود عانل یگری به نام توان را تعریف می کنند. در برنامه Lisrel متغیر توان به عنوان یک متغیر پنهان معرفی می شود.
9- مدل های تعاملی
در مثال های قبلی فرض بر این بود که روابط موجود در مدل ها خطی هستند، به این معنا که همه روابط بین متغیرهای مشاهده شده و پنهان می توانند به وسیله معادلات خطی نشان داده شوند. هرچند که کاربرد اثرات تعاملی و غیرخطی در مدل های رگرسیونی عمومیت دارد، ارائه فرضیه های تعاملی در مدل های مسیر در حداقل است و مثال های بسیار کمی از مدل های عاملی غیرخطی تدارک دیده شده است. در واقع برای چندین دهه مدل سازی معادلات ساختاری برمبنای روابط ساختاری خطی قرار داشته است. اکنون مدل های معادله ساختاری با اثرات تعاملی امکان پذیر است.
در مدل سازی معادلات ساختاری اکنون می توانیم اثرات اصلی و اثرات تعاملی متغیرهای پنهان را آزمون کنیم. در هر حال چندین نوع از اثرات تعاملی وجود دارد. اثرات حاصلضرب متغیرهای مشاهده شده، غیرخطی، مقوله ای و حداقل مربعات دو مرحله ای.
رویکردهای متفاوتی را می توان برای بررسی اثرات تعاملی به کار برد، در ادامه این روش ها معرفی می شوند:
1-9- رویکرد متغیر پیوسته
کنی و جود (1984) روشی را برای آزمون تعامل میان متغیرهای پنهان براساس حاصلضرب های متغیرهای مشاهده شده طرح کرده اند. روش آن ها این امکان را فراهم می آورد که پژوهشگر هر دو نوع جملات درجه دوم و تعاملی را در میان متغیرهای پنهان وارد کند. به عنوان مثال اگر F1 بوسیله متغیرهای مشاهده شده X1 و X2 و F2 بوسیله متغیرهای مشاهده شده X3 و X4 تعریف شده اند، آنگاه تعامل متغیرهای پنهان به عنوان F3 می تواند بوسیله حاصلضرب های متغیرهای مشاهده شده مربوطه تعیین شود؛ یعنی X1X3 ، X1X4 ، X2X3 ، X2X4 . در این رویکرد متغیر پنهان تعاملی F3 می تواند در کنار متغیرهای پنهان اصلی F1 و F2 در معادله ساختاری وارد شود.
2-9- رویکرد متغیر مقوله ای
در این رویکرد نمونه های متفاوتی برحسب سطوح متفاوت متغیرهای تعاملی تعریف شده اند. منطق زیربنایی چنین است که چنانچه اثرات تعاملی وجود داشته باشند، هم اثرات اصلی و هم اثرات تعاملی می توانند با استفاده از نمونه ای متفاوت، به منظور آزمون تفاوت بین مقادیر عرض از مبدأ و ضریب زاویه تدوین شوند. دستیابی به چنین مدلی به وسیله اجرای دو مدل متفاوت امکان پذیر است. مدل اثرات اصلی برای تفاوت های گروهی در حالی که ضریب زاویه را ثابت نگه می داریم و مدل اثرات تعاملی برای تفاوت های گروهی در حالیکه مقادیر عرض از مبدأ و ضریب زاویه برآورد می شوند.
3-9- رویکرد حداقل مربعات دو مرحله ای
بولن (1996و1995) نشان داد که مدل های معادیه ساختاری غیرخطی می توانند به وسیله متغیرهای ابزاری در حداقل مربعات دو مرحله ای برآورد شوند. این روش از دو مرحله تشکیل شده است. در مرحله اول هریک از متغیرهای کمی برونزا در مدل رگرسیون می شوند و مقدار پیش بینی شده از این رگرسیون حاصل می شود.
در مرحله دوم رگرسیون هدف به طور معمول تخمین زده می شود و هر یک از متغیرهای برونزا با مقدار پیش بینی شده از مرحله اول جایگزین می شود. برآوردهای حداقل مربعات دو مرحله ای و خطاهای معیار آن ها بدون تکرار حاصل می شوند و بنابراین اطلاعاتی را بدست می دهد برای پاسخ به این سؤال که آیا مدل تدوین شده قابل دفاع هست یا خیر؟
4-9- مدل های انحنایی رشد پنهان
تحلیل واریانس سنجه های تکرار شده به طور گسترده ای با استفاده از متغیرهای مشاهده شده برای آزمون آماری تغییرات در طول زمان مورد استفاده قرار گرفته اند. مدل سازی معادله ساختاری تحلیل داده های طولی را توسعه داده تا رشد متغیر پنهان را در طول زمان در برگیرد، در حالیکه هم تغییرات منفرد و هم تغییرات طولی را با استفاده از ضریب زاویه و مقادیر عرض از مبدأ به مدل درمی آورد. تحلیل انحنایی رشد پنهان به لحاظ مفهومی مشتمل بر دو تحلیل متفاوت است.
تحلیل اولیه سنجه های تکرار شده در طول زمان، که به طور خطی یا غیرخطی به شکل فرضیه درآمده است.
تحلیل دوم شامل استفاده از پارامترهای منفرد(مقادیر ضریب زاویه و عرض از مبدأ) برای تعیین تفاوت رشد از یک خط مبنا است. مدل انحنایی رشد پنهان تفاوت ها را در طول زمان منعکس کرده و میانگین ها (عرض از مبدأ) و نرخ تغییرات(ضریب زاویه) را در دو سطح فردی و گروهی به حساب می آورد.
در هر حال این رویکرد نیازمند نمونه های بزرگ، داده های دارای توزیع نرمال چندمتغیره، فواصل زمانی مساوی برای همه آزمودنی ها و تغییراتی می باشد که در نتیجه یک پیوستار زمانی رخ می دهند.
5-9- مدل های عاملی پویا
نوعی از کاربردهای مدل سازی معادله ساختاری که شامل متغیرهای پنهان ثابت و غیرثابت در طول زمان، با خطای اندازه گیری تأخیری (همبسته) است به نام تحلیل عاملی پویا خوانده می شود. ویژگی این کاربرد از مدل سازی معادله ساختاری این است که ابزارهای اندازه گیری مشابهی برای آزمودنی های یکسانی در دو یا تعداد بیشتری از موقعیت های زمانی اجرا شده اند.
هدف این تحلیل ارزیابی تغییر در متغیر پنهان بین دو موقعیت مرتب شده، در ارتباط با برخی وقایع یا آزمایش ها است. هنگامی که ابزار اندازه گیری مشابهی در دو یا چند موقعیت زمانی به کار می روند، تمایلی برای وجود خطای اندازه گیری همبسته وجود دارد (خودهمبستگی)

ممنون
با سلام و احترام
با استفاده از مدلسازی تفسیری ساختاری برای استراتژی بازاریابی صادرات به یک مدل 5 سطحی رسیده ام. سپس مزیت های ویژه ای که در اثر بکارگیری چنین استراتژی ای حاصل می شود را تعیین کردم. در نهایت مدل نهایی من شامل: پنح سطح استراتژی بازاریاببی صادرات+ سطح مزیت های ویژه (سه متغیر)+ سطح عملکرد صادرات است.
آیا می توان چنین مدلی را در پی ال اس وارد نمود و ضرایب مسیر را محاسبه نمود؟ چگونه؟ چون من وارد کردم و اعداد غیرمعقولی حاصل شده و تناسب مدل نیز هیچ عددی ندارد.
متشکر میشوم اگر راهنمایی نمایید.
سلام. خير متاسفانه اسمارت پي ال اس براي مدل هاي چند سطحي مناسب نيست.
با سلام و احترام
در الکوی پژوهش من تعداد متغیرهای من خیلی زیاد شده که به تبع باعث شده فرضیات فرعی من خیلی زیاد شود. روشی هست که چندین متغیر رو تحت یک شاخص اندازه گیری کند.
ممنون میشم راهنماییم کنید
با تشکر
سلام. باید از سوالات هر شاخص میانگین بگیرید و برای همان شاخص قرار داد. البته اگر بخواین اثر متغیرهای فرعی رو هم بدونید چاره ای نیست که همه سوالات و متغیرها درون مدل بیاد. اغلب نرم افزار های معادلات ساختاری نظیر لیزرل یا ایموس برای سوالات و متغیرهای زیاد خوب جواب نمیده. برای همین باید تا اونجا که میشه مدل بهینه با سوالات متناسب طراحی کرد
سلام چه آزمونی برای تعیین رابطه همبستگی بین دو متغیر مستقل با دو متغیر وابسته بطور همزمان استفاده می شود؟
سلام. در معادلات ساختاری و نرم افزار لیزرل از همبستگی کانونی استفاده می شود.
سلام و احترام
ببخشید ایا مدل های دارای رابطه های بازگشتی که تأثیر متقابل دو متغیر بر هم را نشان می دهد می توان با مدل یابی معدلات ساختاری در pls بررسی نمود؟ مثلاً متغیر 1 بر متغیر 2 و متغیر 2 بر متغیر 1 اثر دارد و متغیر 1 و 2 هر کدام بر متغیر 3 اثر دارند و متغیر 3 بر متغیر 4 اثر دارد و متغیر 4 اثر بازگشتی بر 1 و 2 دارد؟ میشه بررسیش کرد با pls? مدل از یک تحقیق کیفی بدست آمده.
سپاس
سلام. خیر امکان انجام مدل بازگشتی و روابط متقابل در معادلات ساختاری وجود ندارد.
روابط متقابل را با همبستگی بررسی کنید. چون در معادلات ساختاری یک متغیر نسبت به متغیر دیگر نمی تواند هم مستقل باشد و هم وابسته.
با سلام و احترام
من یک متغیر هدف با دو سطح 1 و 2 دارم. می خواهم ببینم چه متغیرهایی بر سطح دو از متغیر هدف من تاثیر دارد و میزان آن برای هر کدام از متغیرهای تاثیرگذار چقدر است؟ با چه نرم افزاری میتوانم این کار را انجام دهم.؟
سلام. متوجه منظور و علت سوال تان نشدم. بهرحال در معادلات ساختاری بررسی تاثیر بر تمام سطوح متغیر هدف انجام می شود نه فقط یک سطح آن.
می توانید از آزمون تی مستقل و یا مقایسه میانگین ها استفاده نمایید در نرم افزار spss.
سلام.روز بخیر.معذرت میخوام دنبال یک روش اماری بابیس ریلضی قوی هستم که بتونه با درنظر گرفتن تراکم محیط یک مسیربسته باکوتاهترین طول به ما بده؟که ازروش منحنی حداقل مربعات بهتر جواب بده
سلام. متاسفانه در این زمینه نمی توانیم بهتون کمک کنیم.
احتمالا نرم افزار آر و متلب می تواند به شما کمک کند.
سلام. متغیر وابسته یا ملاک من 3 تا است (اضطراب ـ افسردگی ـ وسواس) در معادلات ساختاری در اموس از چه روشی اقدام کنم؟ اصلا آیا میشود چند متغیر وابسته در معادلات ساختاری داشت؟
سلام. اگر متغیر مستقل و وابسته دارید می توانید از ایموس استفاده کنید. به تعداد متغیرها بستگی ندارد.
سلام . در معادلات ساختاری در مدل اندازه گیری وقتی تعداد شاخص ها برای متغیر مکنون زیاد است (مثلا پرسشنامه ای که 30 سوال دارد) آیا باید هر 30 آیتم را به عنوان شاخص برای متغیر مکنون در مدل آورد. حال اگر چندین متغیر مکنون با تعداد زیاد شاخص باشد می توان مدل را در آموس رسم کرد. ممنون از راهنمایتان.
سلام. ۳۰ سوال برای یک متغیر پنهان زیاد هست.
می توانید با تحلیل اکتشافی عامل های جدید داشته باشید و بعد تحلیل تاییدی انجام دهید.
بین لیزرل و آموس تفاوتی نیست
با سلام واحترام
برای مطالعه مدل منحنی رشد مکنون آیا منبعی وجود دارد. ممنون می شوم راهنمایی بفرمایید.
سلام. متاسفانه در این زمینه اطلاعاتی نداریم. سایر دوستان اعلام نظر کنند
سلام من میخوام رابطه علی دو متغیر رو بر یک متغیر دیگر اندازه بگیرم معادلات ساختاری باید استفاده کنم از کدام نرم افزار استفاده ئکنم و ایا در اس پی اس اس موفق میشوم انجام دهم
سلام. هم می توانید از اس پی اس اس استفاده کنید و هم معادلات ساختاری ( نرم افزار های لیزرل یا ایموس یا اسمارت پی ال اس. اگر حجم نمونه کمتر از 200 است از اسمارت پی ال اس باید استفاده کنید).
معادلات ساختاری معتبر تر است و شکل گرافیکی و شاخص های برازش را گزارش می کند.
باسلام و احترام
میخواستم بدونم نحوه بیان فرضیه ها در مدل هایی که هم متغیر مستقل و هم متغیر وابسته دو سطحی است، به چه صورت است. به عنوان مثل فرض کنید من یک متغیر پنهان مستقل به نام “مدیریت دانش” دارم که با دو متغیر پنهان دیگر مثل “جذب دانش” و “کاربرد دانش” سنجیده می شود و یک متغیر پنهان وابسته به نام “عملکرد سازمانی” دارم که با دو متغیر پنهان دیگر به نام “عملکرد مالی” و “عملکرد داخلی” سنجیده می شود. نحوه بیان فرضیه ها در اینچنین مدل دو سطحی چگونه خواهد بود؟
فرضیه اصلی به این صورت است: “مدیریت دانش تأثیر معناداری بر عملکرد سازمانی دارد.”
آیا فرضیه های فرعی زیر برای مدل مذکور صحیح هستند؟
“جذب دانش تأثیر معناداری بر عملکرد سازمانی در جهت بهبود عملکرد مالی دارد.”
“جذب دانش تأثیر معناداری بر عملکرد سازمانی در جهت بهبود عملکرد داخلی دارد.”
“کاربرد دانش تأثیر معناداری بر عملکرد سازمانی در جهت بهبود عملکرد مالی دارد.”
“کاربرد دانش تأثیر معناداری بر عملکرد سازمانی در جهت بهبود عملکرد داخلی دارد.”
سلام. بايد به صورت زير نوشته شود.
“جذب دانش تأثیر معناداری بر عملکرد سازمانی دارد.”
“جذب دانش تأثیر معناداری بر عملکرد مالی دارد.”
سپاسگزارم
با سلام و احترام
ضمن تشکر از زحمات شما دوستان عزیز، سوالی از حضورتون داشتم و چون شما سابقه و تجربه کاریتون در زمینه نرم افزارهای آماری بالاست، میخواستم لطف بفرمایید و راهنماییم کنید. رشته بنده مدیریت جهانگردی هست و پایان نامه ارشدم راجب بررسی تصویر برند مقصد هست که شامل دو جامعه آماری و حجم نمونه 942 هستش، شما برای انجام تحلیل و فصل چهارم پایان نامه نرم افزار ایموس رو پیشنهاد میدید یا نرم افزار لیزرل؟ چون استادم این دو تا نرم افزار رو پیشنهاد دادن، از طرفی تو یه سایت خوندم برای رشته مدیریت از نرم افزار لیزرل استفاده میشه، اما باز یکی از دوستان فرمودند جدیداً برای تحلیل روش های کواریانس محور استفاده از نرم افزار لیزرل اشتباه هست! و اینکه پایان نامه بنده از رو یه مقاله لاتین نوشته شده و روش هم بر اساس همون مقاله انتخاب شده که معادلات ساختاری هست آیا به مشکلی بر نمیخورم بخوام از هر کدوم از این نرم افزارها استفاده کنم؟
سلام. خواهش
چون حجم نمونه تون زياد است مي توانيد از ليزرل استفاده کنيد. فرق زيادي بين ليزرل و ايموس نيست. ولي دانشجويان رشته مديريت بيشتر از ليزرل استفاده مي کنند.
سلام. وقتتون بخیر
ممنون میشم که راهنمایی بفرمایید.
مدل من هم تحلیل عاملی مرتبه اول و هم مرتبه دوم دارد. اگر بخواهم برای رسم مدل کلی، تم های فرعی را به عنوان متغیرهای آشکار در نظر بگیرم، چه باید کرد؟
سلام. باید آنها را با استفاده از میانگین گیری از سوالات مربوط به خودشان به دست آورد و به عنوان متغیرهای آشکار در مدل تعریف کرد.
سپاس بیکران از راهنمایی شما دوست بزرگوار
با سلام و عرض ادب: مدل معادلات ساختاری با مدل معادلات همزمان چه تفاوتی دارند؟
سلام. فرقي ندارند. معادلات ساختاري همه روابط را به صورت همزمان بررسي مي کند.
البته یک بحث معادلات همزمان در اقتصاد سنجی و نرم افزار ایویوز هم داریم که کلا موضوعش با مطالب این سایت تفاوت دارد.
سلام آیا میتوان برای داده های کمی هم مدل ساختاری زد ؟یا فقط برای داده های کیفی امکان پذیر هست؟ و اگر بله چه فرقی با مدل کمی دارد؟آیا مراحل تحلیل و ساخت مدل متفاوت است؟
سلام
من برای تحقیقم دارم اثر مدل مدیریت فناوری رو بر رضایت مشتریان میسنجم. 8 تا معیار برای مدل مدیریت فناوری دراومده و برای رضایت مشتریان 5 تا معیار. منتهی وضعیت مدل مدیریت فناوری رو در سامزانهای تلکام بررسی کردم و یه پرسشنامه در این بخش دارم. یه پرسشنامه هم برای مشتریان و سنجش سطح رضایت اونها توزیع شده
میخوام از طریق معادلات ساختاری این تاثیر رو بررسی کنم. از چی استفاده کنم خوبه؟ PLS دو تا رفرنس داده رو نمیپذیره
سلام. سوال سختی است.
حتی الامکان بایستی یک گروه در تحقیق شرکت کنند. اگر دو گروه پاسخگو هستند باید نمونه ها متناظر باشند (مدیر و مشتری) و تعداد در هر دو گروه یکسان.
اگر به ازای یک مدیر چند مشتری دارند داده های مدیر به تعداد مشتری ها کپی شود
با سلام
مولفه هاي يك متغير مستقل را چگونه بايد در PLS تعريف كرد؟
تحقيق من 2 متغير مستقل دارد كه اولي در قالب 7 مولفه و بعدي 3 مولفه تعريف مي شوند ، سوالات يا شاخص ها را بايد براي هم مولفه ها و هم متغير وابسته تعريف نمايم؟
سلام. بله. شاخص ها و سوالات مربوط به آنها را هم برای متغیرهای مستقل و هم وابسته بایستی تعریف کرد.
با ترسیم فلش بین سوالات و متغیرهای آن، آنها در در PLS تعریف کنید. سایت ویژه PLS این مجموعه:
http://www.smartpls.ir
سلام ببخشید یک سوال داشتم.
در نرم افزار ایموس میشه یه متغیر مستقل و چندتا متغیر وابسته (مثلا 3 تا) داشت؟
وقتی ران میکنم ران نمیشه.
ممنون میشم راهنمایی کنید.
سلام. بله می شود. محدودیتی در تعداد متغیرها ندارد
علل ران نشدن مدل در ایموس می تواند زیاد باشد
با سلام
در لیزرل میتوان یک متغیر مستقل، یک متغیر میانجی و دو متغیر وابسته داشت؟
سلام. بله. محدویتی در نوع متغیر نداره. ولی مدل های خیلی بزرگ و شلوغ را یا برازش نمی کنه یا شاخص برازش رو پایین گزارش می کنه.
با سلام
آیا انجام طرح آشیانه ای با استفاده از نرم افزار SPSS امکان پذیر است؟ ممنون میشم من راهنمایی کنید
سلام. ما با نرم افزار SAS انجام می دهیم. sas بهتر است برای اینکار.
سلام. ببخشید یه سوال، شاید خیلی پیش پا افتاده باشه البته. اگر فقط یه متغیر مستقل و یک متغیر وابسته داشته باشیم (با سه متغیر میانجی) می شه از معادله ساختاری استفاده کرد؟ یا باید حتما تعداد مستقل و وابسته مون بیش تر از یک باشه؟
سلام. بله می تونید استفاده کنید, محدودیتی نداره.
با سلام. متغیر second order به بیان ساده به چه معناست؟ آیا متغیری است که پرسش ها و dimension های متغیرهای دیگر که به آن وارد می شوند، تعیین کننده هستند، یا اینکه خودش دارای dimension ها و سوالات در پرسشنامه است؟
من متغیری دارم که خودش دارای سه بعد است و در پزسشنامه چندین سوال دارد. سه متغیر دیگر هم به این متغیر وارد می شوند که آنها هم هرسه دارای سوال در پرسشنامه هستند و یکی از آن سه ، خودش دارای سه بعد است.
متغیر رده دوم بودن، به کدام یک از این دلایل مرتبط است؟
ممنون از شما
سلام.اگر منظور همان مرتبه اول و مرتبه دوم بودن باشه، متغیرهای دارای بعد فرعی میشن مرتبه دوم
با سلام و احترام
من روش تحقیقم تحلیل تم و آمیخته اکتشافی هست که مدل رو تا حدودی رسیدم . الان سئوالم اینه که من افراد مورد مصاحبه ام خبرگان بانک به تعداد 23 نفر بودن که 11 نفر کارشناس و 12 نفر مدیر ( استاد راهنما گفتن اگه مدیران همکاری نکردن می تونم از کارشناسان بپرسم) آیا باید برای بخش کمی 2 تا پرسشنامه تهیه بشه و آیا دو مجموع دو تا مدل دربیارم ( یکی برای کارشناس و یکی مدیر ) یا یک مدل کافیه ؟ و اینکه برای بخش کمی باید حتما سئوالات به فرضیه تبدیل بشه؟ برای بخش کمی استاد راهنما گفتن مدلسازی معادلات ساختاری و اسمارات پی ال اس تحلیل عاملی تاییدی اما یک کارشناس تحلیلگر گفت بهتره از روش فن دلفی در بخش کمی استفاده کنم آیا این روش در اینجا مصداقی داره؟ mimic و RMSEA چطور؟ . ضمنا حجم نمونه بخش کمی 360 نفر از سه بانک در مجموع هست
سلام. چنانچه فکر میکنین نظرات این دو گروه متفاوت باشه، بله جدا باشن.
برای روش هم اگر مدل مفهومی دارین و در اون نحوه تاثیرگذاری متغیرها بر هم مشخص هست معادلات ساختاری و اگر فقط اکتشاف و استخراج هست دلفی.
معمولا در کارهایی مثل کار شما در مرحله کیفی عوامل استخراج و در مرحله کمی با استفاده از تحلیل تاییدی یا معادلات ساختاری نتایج مرحله کیفی تایید میشن
سلام.
انجام فصل 3 و 4 پایان نامه با تعداد 9 متغیر مستقل و یک متغیر میانجی و یک متغیر وابسته چقدر هزینه دارد.؟؟
سلام برای بررسی اطلاعات رو به شماره ای که داخل سایت است واتساپ بزنید.
سلام و خسته نباشید
من در تحقیقم دو متغیر وابسته دارم که می خوام با هم مقایسشون کنم یعنی اثر متغیرهای وابسته رو رو هردو ببینم و بعد مقایسشون کنم از چه روشی بهتر است استفاده کنم؟و اینکه مثلا میشه از روش ARDL رفت و هر کدوم و جداگانه بررسی کرد و بعد مقایسشون کنم؟
سلام وقت بخیر
آیا برای مدل دو سطحی از نرم افزار اسمارت پی ال اس میشه استفاده کرد؟
سلام. خیر، نمی شود.
با سلام . من یه سوال دارم در باره محاسبه ی میانگین و انحراف معیار برای متغیر های پنهان در تحلیل عاملی تاییدی مرتبه دوم. ایا این در نرم افزار های مثل لیزل شدنیه؟ ایا اصلا این مقادیر قابل محاسبه و تفسیر پذیر هستند؟
سلام و وقت بخیر. در SPSS حساب کنید
با سلام. من دو و احتمالا سه متغیر پیامد باینری با همبستگی دارم و چندین متغیر مستقل که باز اینها هم با هم همخطی و یا همبستگی دارند برای آنالیز چه مدلی پیشنهاد میفرمایید.
راه حل من زدن دو تا Gsem برای هر پیامد و محاسبه ارتباط مستقیم و غیر مستقیم بود به این صورت که اثرات مستقل بر پیامد اول و دوم و اثر پیامد اول هم بر دوم و برای دیگری هم به این ترتیب در این صورت مقدار ضریب پیامدها بر هم رو داریم و این خوب از همبستگی بهتر است.
من با stata کار میکنم اما محدودیتی وجود ندارد اگر راهنمایی بفرمایید ممنون میشم.